Appearance
一、背景
智能工坊测试环境突然宕机了,在看hprof的时候,发现有大量的TokenEncoder对象

因此有点好奇,这个cl100k的encoding到底是干什么的
二、了解
cl100k_base是OpenAI专门为Chat模型设计的字节对编码(BPE)方案,具有以下核心特征:
| 特性 | 数值 | 说明 |
|---|---|---|
| 词汇表大小 | 100,256个Token | 包含100,000个可合并Token和256个特殊Token |
| 支持模型 | GPT-3.5-turbo, GPT-4, text-embedding系列 | 覆盖主流Chat和Embedding模型 |
| 编码效率 | 平均每个Token对应3-4个字符 | 相比原始文本有3-4倍压缩率 |
| 多语言支持 | 支持Unicode字符 | 能够处理中文、英文等多种语言 |
要了解cl100k,就要先了解什么是token编码
在人工智能语言模型的世界里,文本并不是直接处理的字符串,而是经过编码转换的数字序列。OpenAI的Chat模型(如GPT-3.5-turbo、GPT-4等)使用cl100k_base编码器将文本转换为Token(令牌),这种转换直接影响模型的输入输出限制、计算效率和最终性能。
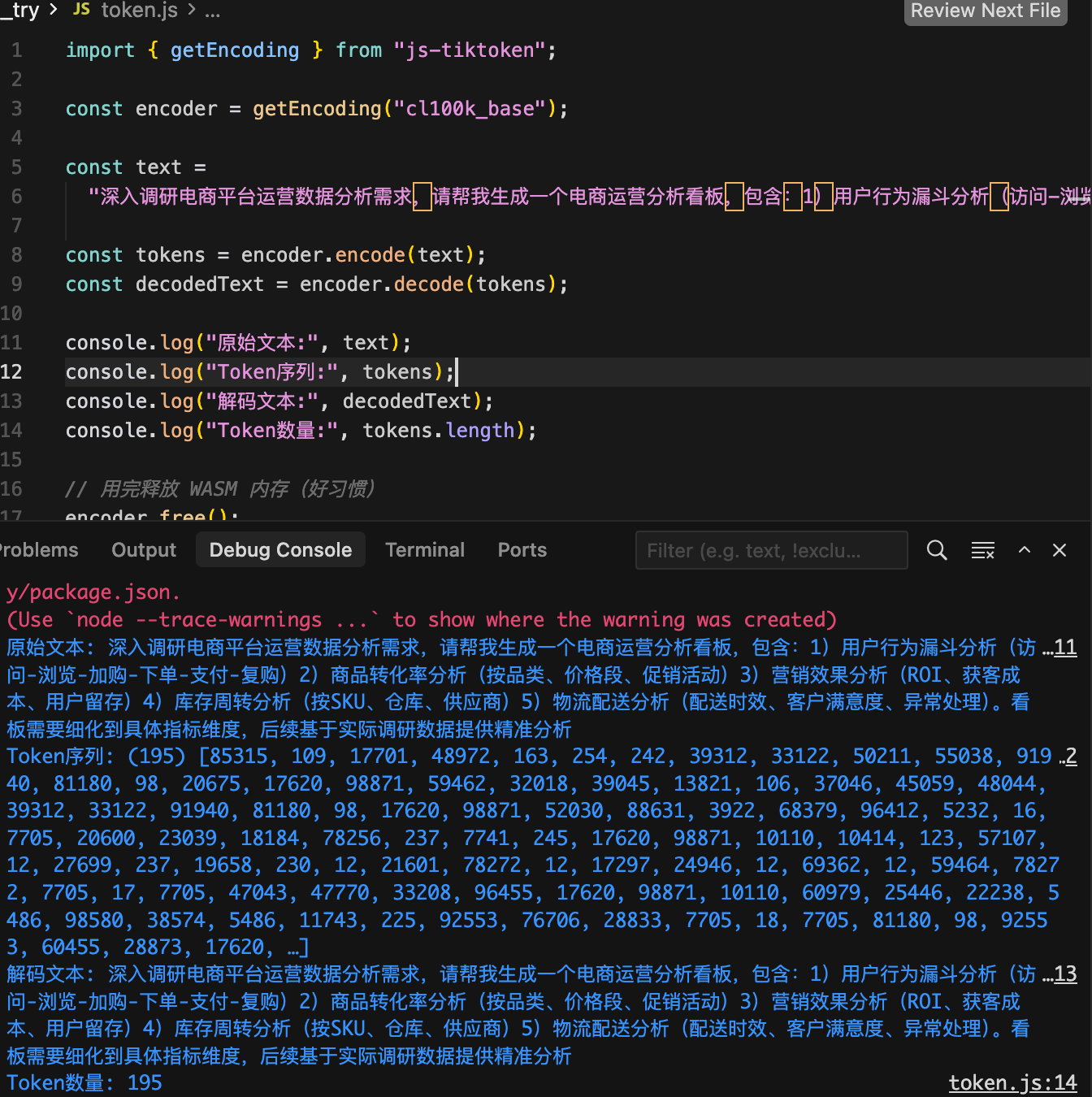
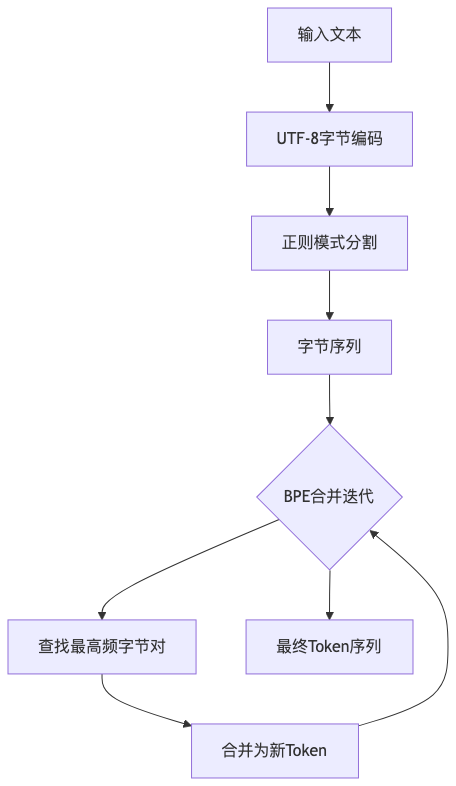
做一些简单了解,算是拓宽知识面了