Appearance
注意力机制(Attention Mechanism)的出现,是从RNN时代走向Transformer时代的关键转折点
一、编码器-解码器
2014年,Sutskever等人提出的序列到序列(Seq2Seq)模型为机器翻译带来了革命性进步,Seq2Seq的核心思想,是将任务拆分成 “理解”和“生成”两个独立的阶段,分别交由编码器(Encoder)和解码器(Decoder)负责
为什么要分离
这种分离的动机来自任务本身的结构,在翻译中,输入是一种语言,输出是另一种语言——他们的词汇、语法、表达方式都不同,将“理解输入”和“生成输出”耦合在同一个模块中会让模型承担过重的负担,将二者分开,让各自专注于一件事,是一种自然的分治策略,这也对应了人类处理此类任务的方式: 先理解原因的意思,再用目标语言去重新表达
编码器的本质
编码器的任务是”理解“
- 将离散的、变长的输入序列转为一组连续的内部表示,在Seq2Seq中,编码器是一个RNN,逐词阅读输入序列,每读一个词就更新自己的隐藏状态,到序列末尾的时候,最终的隐藏状态理论上浓缩了整个输入的语义信息,这个向量称为上下文向量,可以看作编码器对输入的一份理解摘要
编码器的核心价值在于,它将不同长度的文字序列这一结构化输入,统一映射为固定格式的数值表示,为后续的生成提供了可操作的语义基础
解码器的本质
解码器的任务是“生成”
- 在给定编码器提供的语义表示的条件下,逐步构建输出序列,解码器同样是一个RNN,但是它的工作方式和编码器不同,它以编码器的上下文向量作为初始状态,每一步生成一个输出词元,并将这个词元反馈给自己作为下一步的输入,因此,解码器的每次生成都同时依赖两种信息
- 来自解码器的“对输入的理解”
- 自身已经生成的部分内容
这就像一位同声传译员的工作过程:先听完并理解一段话(编码),再逐词地用另一种语言表达出来(解码),每翻译一个词时,既参考对原话的理解,也考虑自己已经说出的部分,确保译文连贯。
协作与信息瓶颈
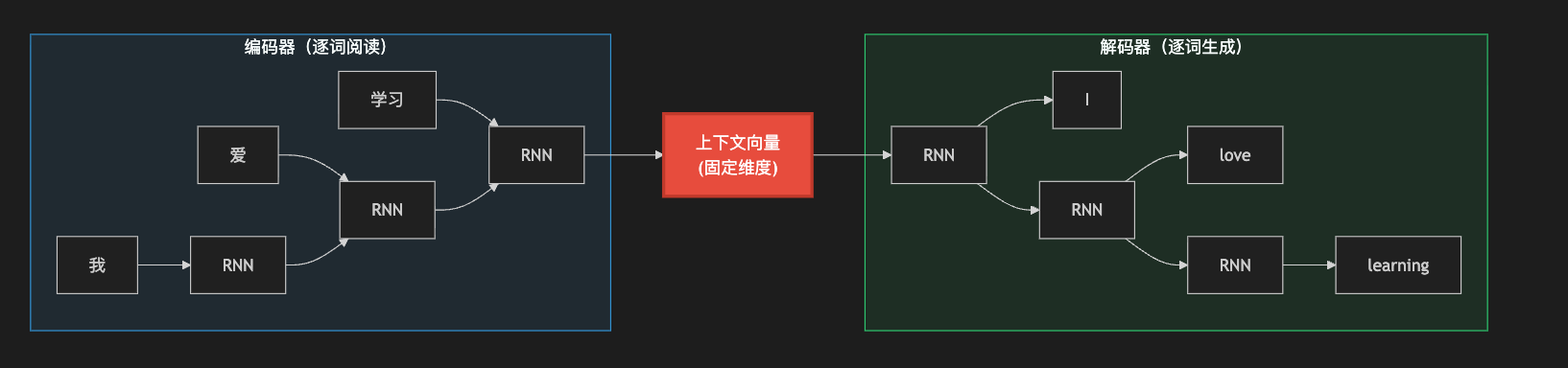
这个架构在短句翻译上效果出色,但在长句上性能急剧下降。原因很直观:无论输入句子有多长,编码器都必须将所有信息压缩到一个固定维度的向量中。 这就像试图把一整本书的内容浓缩成一句话——短文或许做得到,长文必然会丢失大量细节,这个问题被称为信息瓶颈
编码器-解码器的分离是一个影响深远的架构思想。虽然 Seq2Seq 中的信息瓶颈很快就被注意力机制解决,但“理解与生成分离”这一设计理念延续到了 Transformer 时代——Transformer 的原始架构仍然是编码器-解码器结构,而后续的 BERT(仅编码器)、GPT(仅解码器)和 T5(编码器-解码器)则分别发展了这一思想的不同侧面
二、Bahdanau注意力
- 英语近似发音:/ˌbɑːdˈnaʊ/
- 可拆读为:bahd-NOW
2015年,Bahdanau等人提出了一个优雅的解决方案:在解码每个词时,不再只看那一个固定的上下文向量,而是让解码器回头看编码器在每个位置产生的隐藏状态,并自动决定关注哪些位置
💡
为什么要看“隐藏状态”而不是原始的输入词向量?RNN 在每个时间步产生的隐藏状态
h_j,不仅编码了当前位置的词,还融合了它之前所有词的上下文信息。换句话说,h_1只知道第一个词,但h_3已经“读过”了前三个词,它对第三个词的表示是带着上下文理解的。如果直接看原始词向量,“苹果”在“吃苹果”和“苹果公司”中的表示完全一样,无法区分语义;而隐藏状态则已经融入了上下文,能区分这两种含义。
因此,隐藏状态是编码器在每个位置留下的“带上下文的阅读笔记”,比原始词向量包含了更丰富、更准确的信息,是注意力机制理想的关注对象。
这个想法的直觉非常自然,以翻译为例:翻译一个英文句子中的某个法语词时,并不需要同等地关注源句子中的每一个词——通常只需要特别留意与当前翻译相关的几个词。注意力机制让模型自动学会了这种选择性关注。
网上的计算过程:

其中,对齐分数的计算方式有多种。Bahdanau 使用了一个小型前馈网络
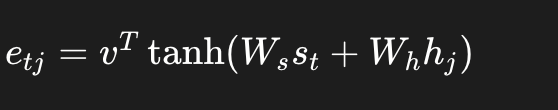
这种方式也被称为加性注意力(Additive Attention),因为它将两个向量线性变换后相加
注意力机制的效果是显著的。它不仅大幅提升了长句翻译的质量,还提供了一个宝贵的副产品:可解释性。通过可视化注意力权重矩阵,可以清晰地看到翻译每个目标词时,模型关注了源句子中的哪些位置
三、从加性注意力到点积注意力
Luong 等人在 2015 年提出了更简洁的点积注意力(Dot-Product Attention):
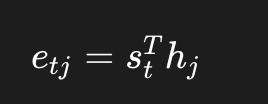
直接计算两个向量的点积作为相关性分数。这种方式不需要额外的可学习参数,计算效率更高(可以用矩阵乘法批量完成),且在实践中效果相当。
点积的数学含义是衡量两个向量的”相似度“:方向越接近的两个向量,点积值越大。因此,点积注意力的直觉是:解码器在寻找与自己当前状态最”相似“的编码器位置。
这种从加性到乘性(点积)的简化看似微小,却为后来 Transformer 的高效计算铺平了道路——在 Transformer 中,所有注意力计算都基于点积,正是因为点积可以利用高度优化的矩阵乘法库在 GPU 上极其高效地执行。
四、注意力带来的根本变化
第一,打破了信息瓶颈。 解码器不再依赖一个固定大小的向量,而是可以访问编码器在每个位置的完整表示。信息容量不再受限于一个向量的维度。
第二,缩短了信息传递路径。 在传统的 Seq2Seq 中,源句子第一个词的信息必须依次通过所有时间步才能到达解码器,路径长度为 O(n)。有了注意力机制,解码器可以直接”看到“任意源位置,路径长度降为 O(1)。
然而,这一阶段的注意力机制仍然是”附属品”——它被嫁接在 RNN 之上,编码器和解码器仍然是 LSTM 或 GRU。RNN 的串行计算瓶颈依然存在。一个自然的问题出现了:既然注意力机制已经能够直接连接任意两个位置,那还需要 RNN 吗?因此,出现了Transformer