Appearance
Transformer 结构主要由 Encoder、Decoder 两个部分组成,两个部分分别具有不一样的结构和输入输出。
针对 Encoder、Decoder 的特点,引入 ELMo 的预训练思路,开始出现不同的、对 Transformer 进行优化的思路。例如,Google 仅选择了 Encoder 层,通过将 Encoder 层进行堆叠,再提出不同的预训练任务-掩码语言模型(Masked Language Model,MLM),打造了一统自然语言理解(Natural Language Understanding,NLU)任务的代表模型——BERT。而 OpenAI 则选择了 Decoder 层,使用原有的语言模型(Language Model,LM)任务,通过不断增加模型参数和预训练语料,打造了在 NLG(Natural Language Generation,自然语言生成)任务上优势明显的 GPT 系列模型,也是现今大火的 LLM 的基座模型。当然,还有一种思路是同时保留 Encoder 与 Decoder,打造预训练的 Transformer 模型,例如由 Google 发布的 T5模型。
一、BERT
BERT,全名为 Bidirectional Encoder Representations from Transformers,是由 Google 团队在 2018年发布的预训练语言模型。该模型发布于论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,实现了包括 GLUE、MultiNLI 等七个自然语言处理评测任务的最优性能(State Of The Art,SOTA),堪称里程碑式的成果。自 BERT 推出以来,预训练+微调的模式开始成为自然语言处理任务的主流,不仅 BERT 自身在不断更新迭代提升模型性能,也出现了如 MacBERT、BART 等基于 BERT 进行优化提升的模型。可以说,BERT 是自然语言处理的一个阶段性成果,标志着各种自然语言处理任务的重大进展以及预训练模型的统治地位建立,一直到 LLM 的诞生,NLP 领域的主导地位才从 BERT 系模型进行迁移。即使在 LLM 时代,要深入理解 LLM 与 NLP,BERT 也是无法绕过的一环。
BERT是一个统一了多种思想的预训练模型,其所沿承的核心思想包括
- Transformer架构,在 2017年发表的《Attention is All You Need》论文提出了完全使用 注意力机制而抛弃 RNN、LSTM 结构的 Transformer 模型,带来了新的模型架构。BERT 正沿承了 Transformer 的思想,在 Transformer 的模型基座上进行优化,通过将 Encoder 结构进行堆叠,扩大模型参数,打造了在 NLU 任务上独居天分的模型架构;
- 预训练+微调范式。同样在 2018年,ELMo 的诞生标志着预训练+微调范式的诞生。ELMo 模型基于双向 LSTM 架构,在训练数据上基于语言模型进行预训练,再针对下游任务进行微调,表现出了更加优越的性能,将 NLP 领域导向预训练+微调的研究思路。而 BERT 也采用了该范式,并通过将模型架构调整为 Transformer,引入更适合文本理解、能捕捉深层双向语义关系的预训练任务 MLM,将预训练-微调范式推向了高潮。
模型架构
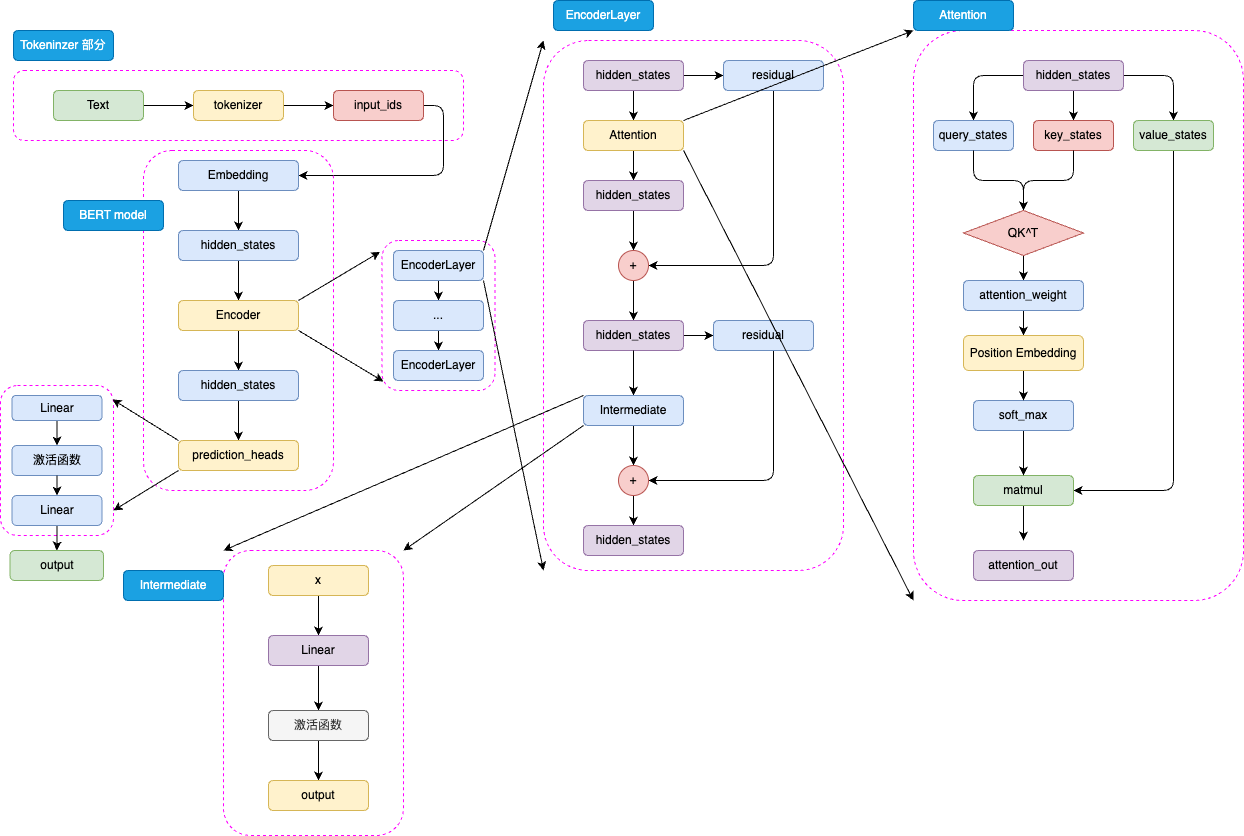
BERT 的模型架构是取了 Transformer 的 Encoder 部分堆叠而成
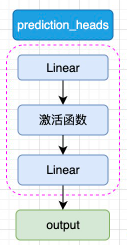
BERT 是针对于 NLU 任务打造的预训练模型,其输入一般是文本序列,而输出一般是 Label,例如情感分类的积极、消极 Label。但是,正如 Transformer 是一个 Seq2Seq 模型,使用 Encoder 堆叠而成的 BERT 本质上也是一个 Seq2Seq 模型,只是没有加入对特定任务的 Decoder,因此,为适配各种 NLU 任务,在模型的最顶层加入了一个分类头 prediction_heads,用于将多维度的隐藏状态通过线性层转换到分类维度(例如,如果一共有两个类别,prediction_heads 输出的就是两维向量)。
模型整体既是由 Embedding、Encoder 加上 prediction_heads 组成:
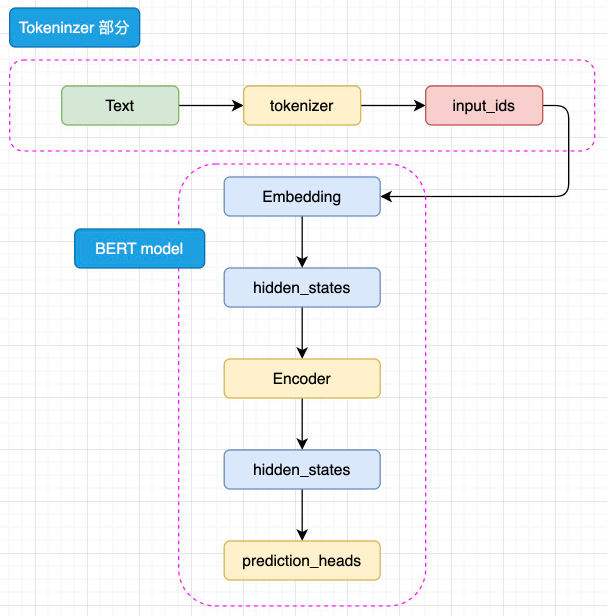
输入的文本序列会首先通过 tokenizer(分词器) 转化成 input_ids(基本每一个模型在 tokenizer 的操作都类似,可以参考 Transformer 的 tokenizer 机制,后文不再赘述),然后进入 Embedding 层转化为特定维度的 hidden_states,再经过 Encoder 块。Encoder 块中是堆叠起来的 N 层 Encoder Layer,BERT 有两种规模的模型,分别是 base 版本(12层 Encoder Layer,768 的隐藏层维度,总参数量 110M),large 版本(24层 Encoder Layer,1024 的隐藏层维度,总参数量 340M)。通过Encoder 编码之后的最顶层 hidden_states 最后经过 prediction_heads 就得到了最后的类别概率,经过 Softmax 计算就可以计算出模型预测的类别。
BERT 采用 WordPiece 作为分词方法。WordPiece 是一种基于统计的子词切分算法,其核心在于将单词拆解为子词(例如,"playing" -> ["play", "##ing"])。其合并操作的依据是最大化语言模型的似然度。对于中文等非空格分隔的语言,通常将单个汉字作为原子分词单位(token)处理。
prediction_heads 其实就是线性层加上激活函数,一般而言,最后一个线性层的输出维度和任务的类别数相等
而每一层 Encoder Layer 都是和 Transformer 中的 Encoder Layer 结构类似的层
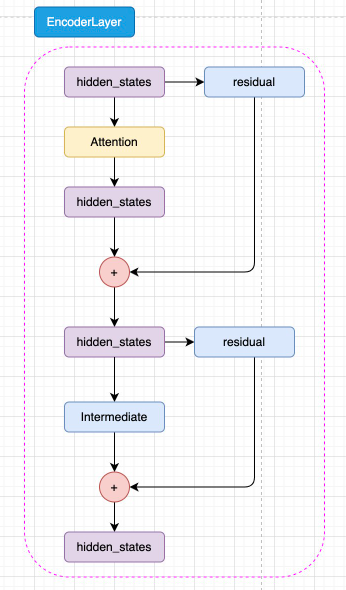
已经通过 Embedding 层映射的 hidden_states 进入核心的 attention 机制,然后通过残差连接的机制和原输入相加,再经过一层 Intermediate 层得到最终输出。Intermediate 层是 BERT 的特殊称呼,其实就是一个线性层加上激活函数:
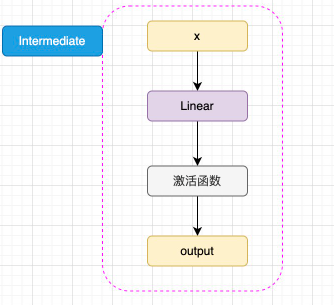
注意,BERT 所使用的激活函数是 GELU 函数,全名为高斯误差线性单元激活函数,这也是自 BERT 才开始被普遍关注的激活函数
BERT 的 注意力机制和 Transformer 中 Encoder 的 自注意力机制几乎完全一致,但是 BERT 将相对位置编码融合在了注意力机制中,将相对位置编码同样视为可训练的权重参数
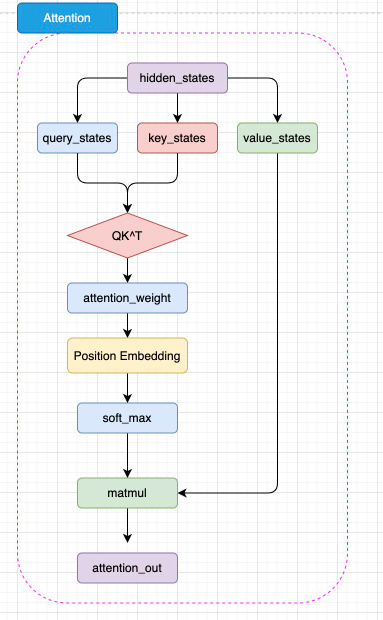
BERT 的注意力计算过程和 Transformer 的唯一差异在于,在完成注意力分数的计算之后,先通过 Position Embedding 层来融入相对位置信息。这里的 Position Embedding 层,其实就是一层线性矩阵。通过可训练的参数来拟合相对位置,相对而言比 Transformer 使用的绝对位置编码 Sinusoidal 能够拟合更丰富的相对位置信息,但是,这样也增加了不少模型参数,同时完全无法处理超过模型训练长度的输入(例如,对 BERT 而言能处理的最大上下文长度是 512 个 token)。
注:原始 BERT(即论文提出)使用和 Transformer 一致的绝对位置编码,后续改进(包括 BERT 的各种变体)使用了上述相对位置编码,为帮助了解更全面的模型结构设计,此处选择了改进版 BERT。
可以看出,BERT 的模型架构既是建立在 Transformer 的 Encoder 之上的,这也是为什么说 BERT 沿承了 Transformer 的思想。
预训练任务——MLM+NSP
相较于基本沿承 Transformer 的模型架构,BERT 更大的创新点在于其提出的两个新的预训练任务上——MLM 和 NSP(Next Sentence Prediction,下一句预测)。预训练-微调范式的核心优势在于,通过将预训练和微调分离,完成一次预训练的模型可以仅通过微调应用在几乎所有下游任务上,只要微调的成本较低,即使预训练成本是之前的数倍甚至数十倍,模型仍然有更大的应用价值。因此,可以进一步扩大模型参数和预训练数据量,使用海量的预训练语料来让模型拟合潜在语义与底层知识,从而让模型通过长时间、大规模的预训练获得强大的语言理解和生成能力。
因此,预训练数据的核心要求即是需要极大的数据规模(数亿 token)。毫无疑问,通过人工标注产出的全监督数据很难达到这个规模。因此,预训练数据一定是从无监督的语料中获取。这也是为什么传统的预训练任务都是 LM 的原因——LM 使用上文预测下文的方式可以直接应用到任何文本中,对于任意文本,我们只需要将下文遮蔽将上文输入模型要求其预测就可以实现 LM 训练,因此互联网上所有文本语料都可以被用于预训练。
但是,LM 预训练任务的一大缺陷在于,其直接拟合从左到右的语义关系,但忽略了双向的语义关系。虽然 Transformer 中通过位置编码表征了文本序列中的位置信息,但这和直接拟合双向语义关系还是有本质区别。例如,BiLSTM(双向 LSTM 模型)在语义表征上就往往优于 LSTM 模型,就是因为 BiLSTM 通过双向的 LSTM 拟合了双向语义关系。因此,有没有一种预训练任务,能够既利用海量无监督语料,又能够训练模型拟合双向语义关系的能力?
基于这一思想,Jacob 等学者提出了 MLM,也就是掩码语言模型作为新的预训练任务。相较于模拟人类写作的 LM,MLM 模拟的是“完形填空”。MLM 的思路也很简单,在一个文本序列中随机遮蔽部分 token,然后将所有未被遮蔽的 token 输入模型,要求模型根据输入预测被遮蔽的 token。例如,输入和输出可以是:
输入:I <MASK> you because you are <MASK>
输出:<MASK> - love; <MASK> - wonderful由于模型可以利用被遮蔽的 token 的上文和下文一起理解语义来预测被遮蔽的 token,因此通过这样的任务,模型可以拟合双向语义,也就能够更好地实现文本的理解。同样,MLM 任务无需对文本进行任何人为的标注,只需要对文本进行随机遮蔽即可,因此也可以利用互联网所有文本语料实现预训练。例如,BERT 的预训练就使用了足足 3300M 单词的语料。
不过,MLM 也存在其固有缺陷。LM 任务模拟了人自然创作的过程,其训练和下游任务是完全一致的,也就是说,训练时是根据上文预测下文,下游任务微调和推理时也同样如此。但是 MLM 不同,在下游任务微调和推理时,其实是不存在我们人工加入的 <MASK> 的,我们会直接通过原文本得到对应的隐藏状态再根据下游任务进入分类器或其他组件。预训练和微调的不一致,会极大程度影响模型在下游任务微调的性能。针对这一问题,作者对 MLM 的策略进行了改进。
在具体进行 MLM 训练时,会随机选择训练语料中 15% 的 token 用于遮蔽。但是这 15% 的 token 并非全部被遮蔽为 <MASK>,而是有 80% 的概率被遮蔽,10% 的概率被替换为任意一个 token,还有 10% 的概率保持不变。其中 10% 保持不变就是为了消除预训练和微调的不一致,而 10% 的随机替换核心意义在于迫使模型保持对上下文信息的学习。因为如果全部遮蔽的话,模型仅需要处理被遮蔽的位置,从而仅学习要预测的 token 而丢失了对上下文的学习。通过引入部分随机 token,模型无法确定需要预测的 token,从而被迫保持每一个 token 的上下文表征分布,从而具备了对句子的特征表示能力。且由于随机 token 的概率很低,其并不会影响模型实质的语言理解能力。
除去 MLM,BERT 还提出了另外一个预训练任务——NSP,即下一个句子预测。NSP 的核心思想是针对句级的 NLU 任务,例如问答匹配、自然语言推理等。问答匹配是指,输入一个问题和若干个回答,要求模型找出问题的真正回答;自然语言推理是指,输入一个前提和一个推理,判断推理是否是符合前提的。这样的任务都需要模型在句级去拟合关系,判断两个句子之间的关系,而不仅是 MLM 在 token 级拟合的语义关系。因此,BERT 提出了 NSP 任务来训练模型在句级的语义关系拟合。
NSP 任务的核心思路是要求模型判断一个句对的两个句子是否是连续的上下文。例如,输入和输入可以是:
输入:
Sentence A:I love you.
Sentence B: Because you are wonderful.
输出:
1(是连续上下文)
输入:
Sentence A:I love you.
Sentence B: Because today's dinner is so nice.
输出:
0(不是连续上下文)通过要求模型判断句对关系,从而迫使模型拟合句子之间的关系,来适配句级的 NLU 任务。同样,由于 NSP 的正样本可以从无监督语料中随机抽取任意连续的句子,而负样本可以对句子打乱后随机抽取(只需要保证不要抽取到原本就连续的句子就行),因此也可以具有几乎无限量的训练数据。
在具体预训练时,BERT 使用了 800M 的 BooksCorpus 语料和 2500M 的英文维基百科语料,90% 的数据使用 128 的上下文长度训练,剩余 10% 的数据使用 512 作为上下文长度进行预训练,总共约训练了 3.3B token。其训练的超参数也是值得关注的,BERT 的训练语料共有 13GB 大小,其在 256 的 batch size 上训练了 1M 步(40 个 Epoch)。而相较而言,LLM 一般都只会训练一个 Epoch,且使用远大于 256 的 batch size。
可以看到,相比于传统的非预训练模型,其训练的数据量有指数级增长。当然,更海量的训练数据需要更大成本的算力,BERT 的 Base 版本和 Large 版本分别使用了 16块 TPU 和 64块 TPU 训练了 4天才完成。
下游任务微调
作为 NLP 领域里程碑式的成果,BERT 的一个重大意义就是正式确立了预训练-微调的两阶段思想,即在海量无监督语料上进行预训练来获得通用的文本理解与生成能力,再在对应的下游任务上进行微调。该种思想的一个重点在于,预训练得到的强大能力能否通过低成本的微调快速迁移到对应的下游任务上。
针对这一点,BERT 设计了更通用的输入和输出层来适配多任务下的迁移学习。对每一个输入的文本序列,BERT 会在其首部加入一个特殊 token <CLS>。在后续编码中,该 token 代表的即是整句的状态,也就是句级的语义表征。在进行 NSP 预训练时,就使用了该 token 对应的特征向量来作为最后分类器的输入。
在完成预训练后,针对每一个下游任务,只需要使用一定量的全监督人工标注数据,对预训练的 BERT 在该任务上进行微调即可。所谓微调,其实和训练时更新模型参数的策略一致,只不过在特定的任务、更少的训练数据、更小的 batch_size 上进行训练,更新参数的幅度更小。对于绝大部分下游任务,都可以直接使用 BERT 的输出。例如,对于文本分类任务,可以直接修改模型结构中的 prediction_heads 最后的分类头即可。对于序列标注等任务,可以集成 BERT 多层的隐含层向量再输出最后的标注结果。对于文本生成任务,也同样可以取 Encoder 的输出直接解码得到最终生成结果。因此,BERT 可以非常高效地应用于多种 NLP 任务。
BERT 一经提出,直接在 NLP 11个赛道上取得 SOTA 效果,成为 NLU 方向上当之无愧的霸主,后续若干在 NLU 任务上取得更好效果的模型都是在 BERT 基础上改进得到的。直至 LLM 时代,BERT 也仍然能在很多标注数据丰富的 NLU 任务上达到最优效果,事实上,对于某些特定、训练数据丰富且强调高吞吐的任务,BERT 比 LLM 更具有可用性。
RoBERTa
BERT 作为 NLP 划时代的杰作,同时在多个榜单上取得 SOTA 效果,也带动整个 NLP 领域向预训练模型方向迁移。以 BERT 为基础,在多个方向上进行优化,还涌现了一大批效果优异的 Encoder-Only 预训练模型。它们大都有和 BERT 类似或完全一致的模型结构,在训练数据、预训练任务、训练参数等方面上进行了优化,以取得能力更强大、在下游任务上表现更亮眼的预训练模型。其中之一即是同样由 Facebook 发布的 RoBERTa。
前面我们说过,预训练-微调的一个核心优势在于可以使用远大于之前训练数据的海量无监督语料进行预训练。因为在传统的深度学习范式中,对每一个任务,我们需要从零训练一个模型,那么就无法使用太大的模型参数,否则需要极大规模的有监督数据才能让模型较好地拟合,成本太大。但在预训练-微调范式,我们在预训练阶段可以使用尽可能大量的训练数据,只需要一次预训练好的模型,后续在每一个下游任务上通过少量有监督数据微调即可。而 BERT 就使用了 13GB(3.3B token)的数据进行预训练,这相较于传统 NLP 来说是一个极其巨大的数据规模了。
但是,13GB 的预训练数据是否让 BERT 达到了充分的拟合呢?如果我们使用更多预训练语料,是否可以进一步增强模型性能?更多的,BERT 所选用的预训练任务、训练超参数是否是最优的?RoBERTa 应运而生。
todo:...