Appearance
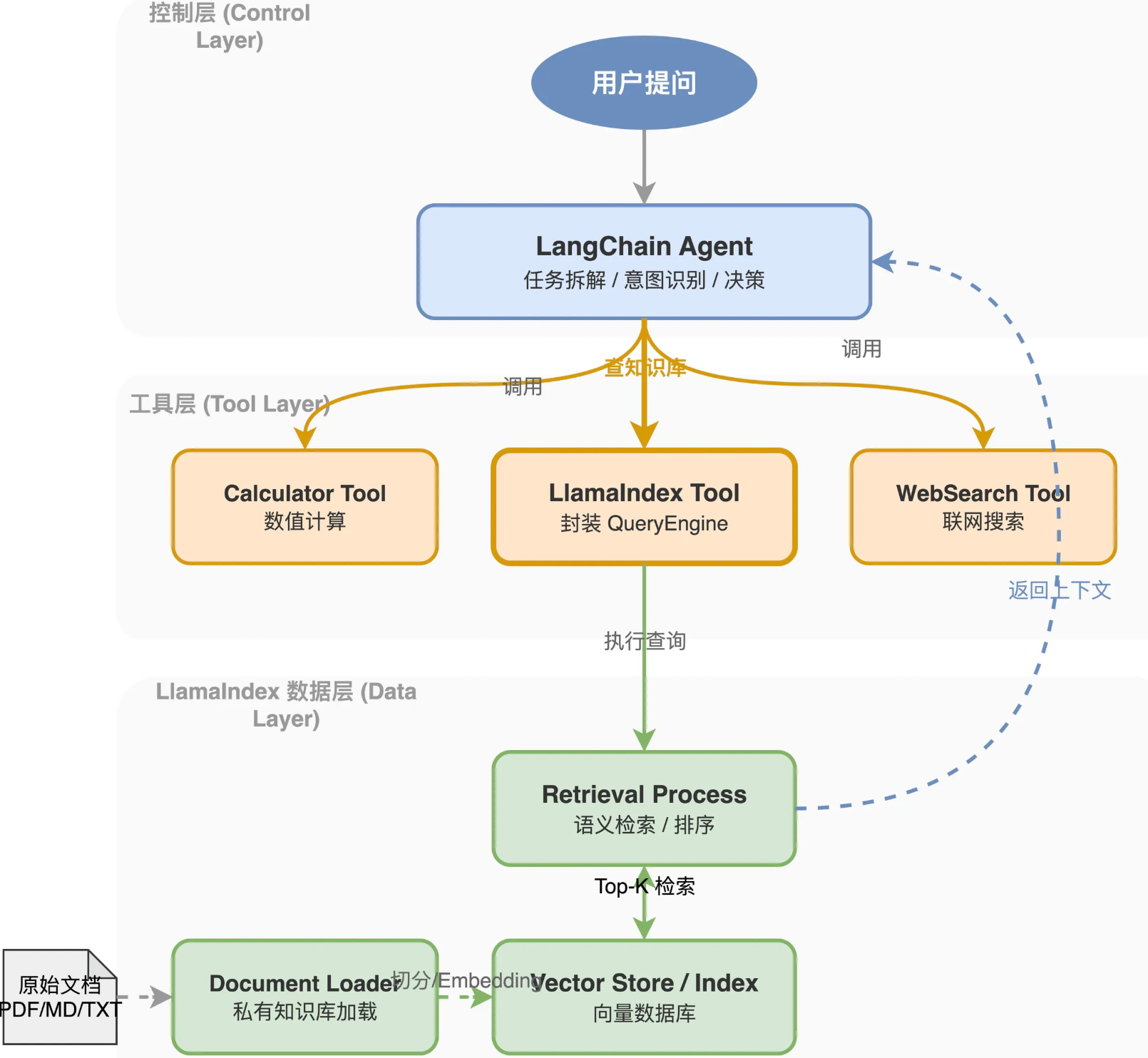
LlamaIndex和LangChain结合的核心思路是把LlamaIndex的检索能力包装成LangChain的Tool,让LangChain的agent在需要查资料的时候调用它
LlamaIndex擅长数据索引和检索,对各种文档格式的解析、向量化、多种检索策略支持的很全
LangChain则擅长编排复杂流程,链式调用,agent决策,多工具决策
最常见的集成方式是用LlamaIndex提供的LlamaIndexTool
python
from llama_index.core.langchain_helpers.agents import (
IndexToolConfig,
LlamaIndexTool,
)
tool_config = IndexToolConfig(
query_engine=query_engine,
name="Vector Index",
description="Useful for answering queries about X",
tool_kwargs={"return_direct": True},
)
tool = LlamaIndexTool.from_tool_config(tool_config)这样LangChain的agent就能够像调用其他工具一样调用LlamaIndex的查询引擎了
整体架构分三层
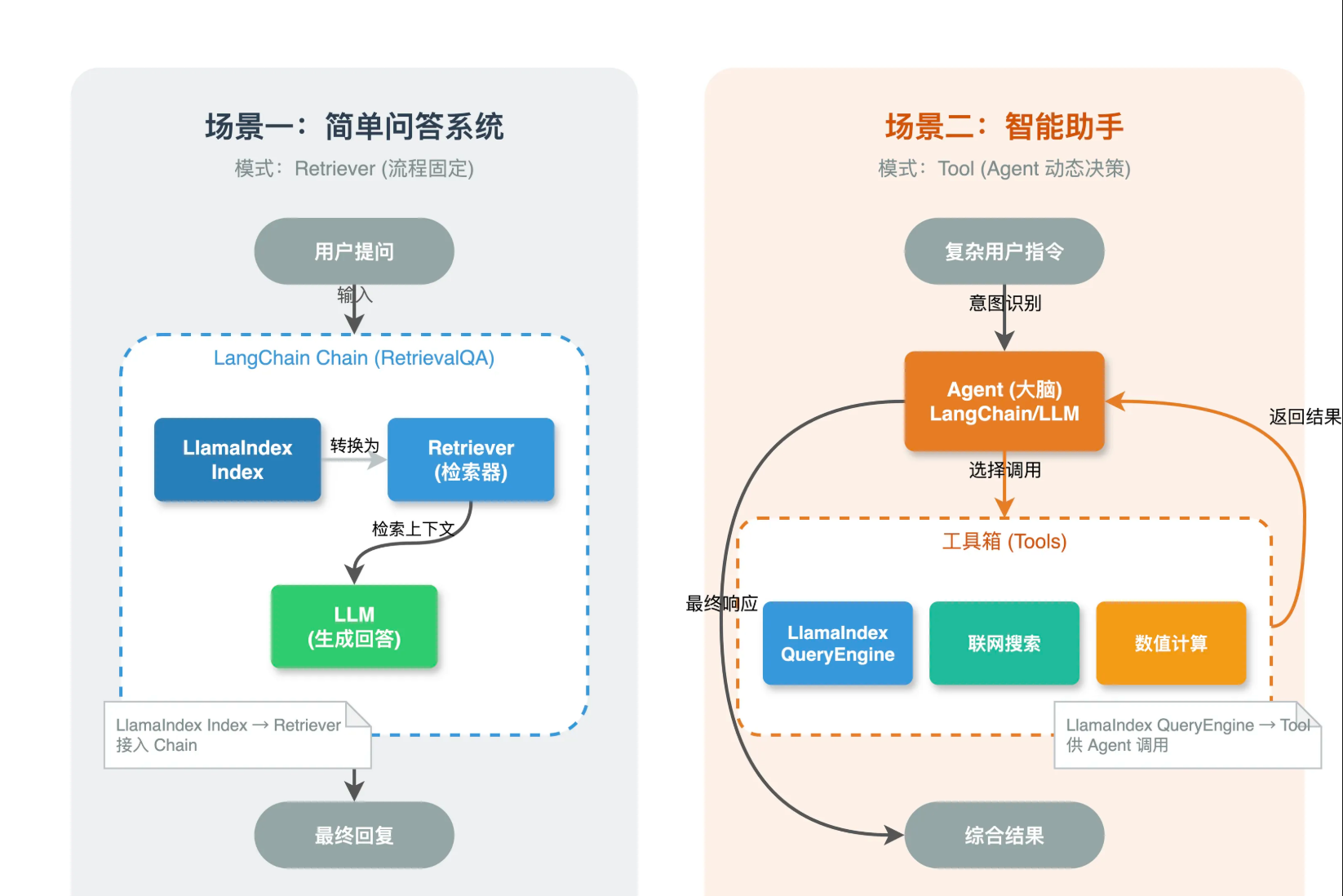
集成除了Tool模式,还有Retriever模式
https://docs.langchain.com/oss/python/integrations/retrievers
把LlamaIndex的Index转成LangChain的Retriever接口,直接嵌入到LangChain的Chain里,适合流程固定,不需要agnet决策的场景
python
from llama_index.core import VectorStoreIndex
# 创建 LlamaIndex 索引
index = VectorStoreIndex.from_documents(documents)
# 转成 LangChain Retriever
retriever = index.as_retriever()
# 在 LangChain Chain 里使用
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever
)数据加载器的复用
LlamaIndex的Data Loader支持100多种数据源,PDF、Word、网页、数据库都能直接读
这些Loader也能转成LangChain的Document格式复用
python
from llama_index.core import SimpleDirectoryReader
# 用 LlamaIndex 的 Loader 加载文档
documents = SimpleDirectoryReader("./data").load_data()
# 转成 LangChain Document 格式
langchain_docs = [doc.to_langchain_format() for doc in documents]如果项目已经用了LlamaIndex做文档解析,就不用重新写LangChain的Loader,直接转格式就行