Appearance
RAG(检索增强生成),本质上就是给大模型外挂一个外部知识库
大模型有两个硬伤,一个是知识有滞后性,训练的数据截止到某个知识点,不知道最近的事,
二是不懂私有数据,没有见过各个公司的内部文档或者其他内部数据,rag就是用来解决这个问题的
核心流程可以概括为三步
- 找
- 用户提问的时候,先不问大模型,而是去向量数据库把跟问题相关的资料片段找出来
- 缝
- 把用户的问题和刚才找到的资料片段缝合在一起,变成一个信息量更大的prompt
- 写
- 把缝好的prompt喂给大模型,这样大模型就可以根据我们提供的资料生成准确的答案
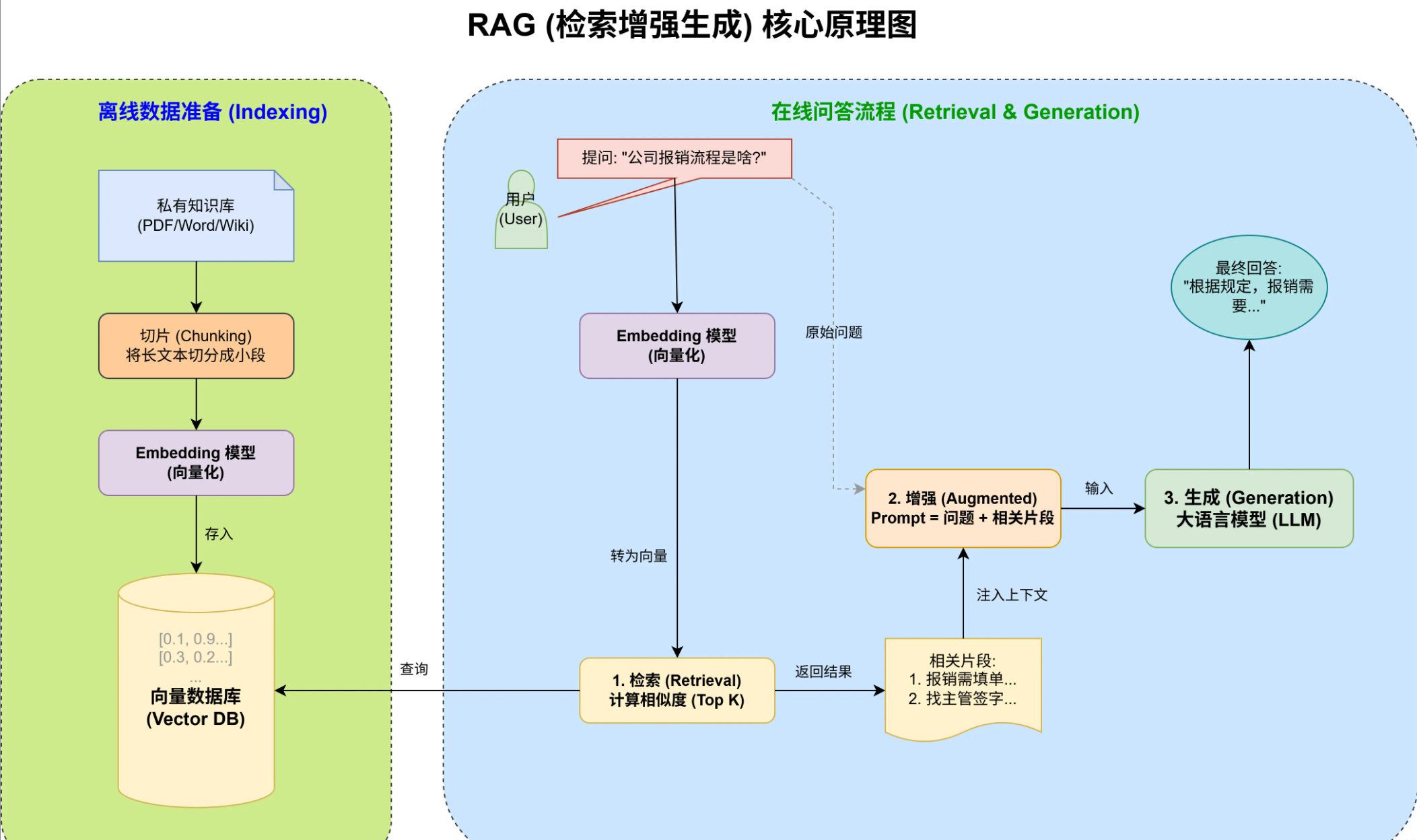
RAG的详细工作流程
- 1、文本向量化
- 用语义模型把文档和问题转为高维向量
- 2、向量数据库检索
- 用Milvus这类向量数据库存储所有文档向量,用户提问后对问题做向量化,然后在数据库中做最邻近搜索,找出语义最接近的N条内容
- 3、构建prompt,把用户原始问题和检索到的内容拼接形成上下文
- 4、生成回答
rag也有一些局限性
- 检索质量决定上线,如果向量数据库里的文档本身质量很差,或者Embedding模型语义理解不到位,检索出来的就是垃圾
- 上下文窗口有限,如果检索的内容太多塞不下,就得做截断或者rerank
- 实时性受限于索引更新,知识库如果更新不及时也会有过时回答
常见问题
如果检索出来的文档片段太多,超过了大模型的上下文窗口
- 常见做法有三种
- 做Rerank,用一个排序模型对检索结果重新打分,只保留最相关的Top-k条
- 做摘要压缩,对检索出来的长文档跑一边摘要,信息密度提上去
- 分块处理,把问题拆分成多个子问题分别检索回答,最后在做汇总
实际项目里,Rerank+Top-k阶段是最常用的组合
RAG和模型微调的区别,什么场景下选什么
- 微调是把知识刻进模型参数里,适合需要改变模型行为风格或者学习特定任务场景的场景,比如让模型用特定语气说话,微调一次成本高,知识更新要重新训练
- RAG是把知识放在外部,适合知识频繁更新,需要引用来源或者私有数据量大的情况
向量检索找到的内容语义相近,但可能不是真正相关的,怎么解决
- 向量相似不等于真正相关,常见解决方案
- 混合检索,把向量检索和关键词检索结合起来,用BM25这类传统检索补一刀
- 加Rerank层,用交叉编码器对候选文档做精排,过滤掉语义漂移的结果
- 优化分块策略,文档切的太碎容易丢失上下文,切的太大又不够精准,需要根据具体业务调整chunk size和overlap
文档分块策略
常见策略
- 语义切分:用SemanticSplitter等工具,保证每个块语义完整独立,比如一个问答对不会被切成两块
- 结构切分:HTML、PDF这类有层级的文档,可以按照标题层级切割,像HTMLHeaderTextSplitter
- 递归切分:RecursiveCharacterTextSplitter ,先按大的分隔符切割,切不动了再按小的,兼顾连贯性和长度限制
实际项目里,300-500字一块是比较通用的起点
