Appearance
查询扩展
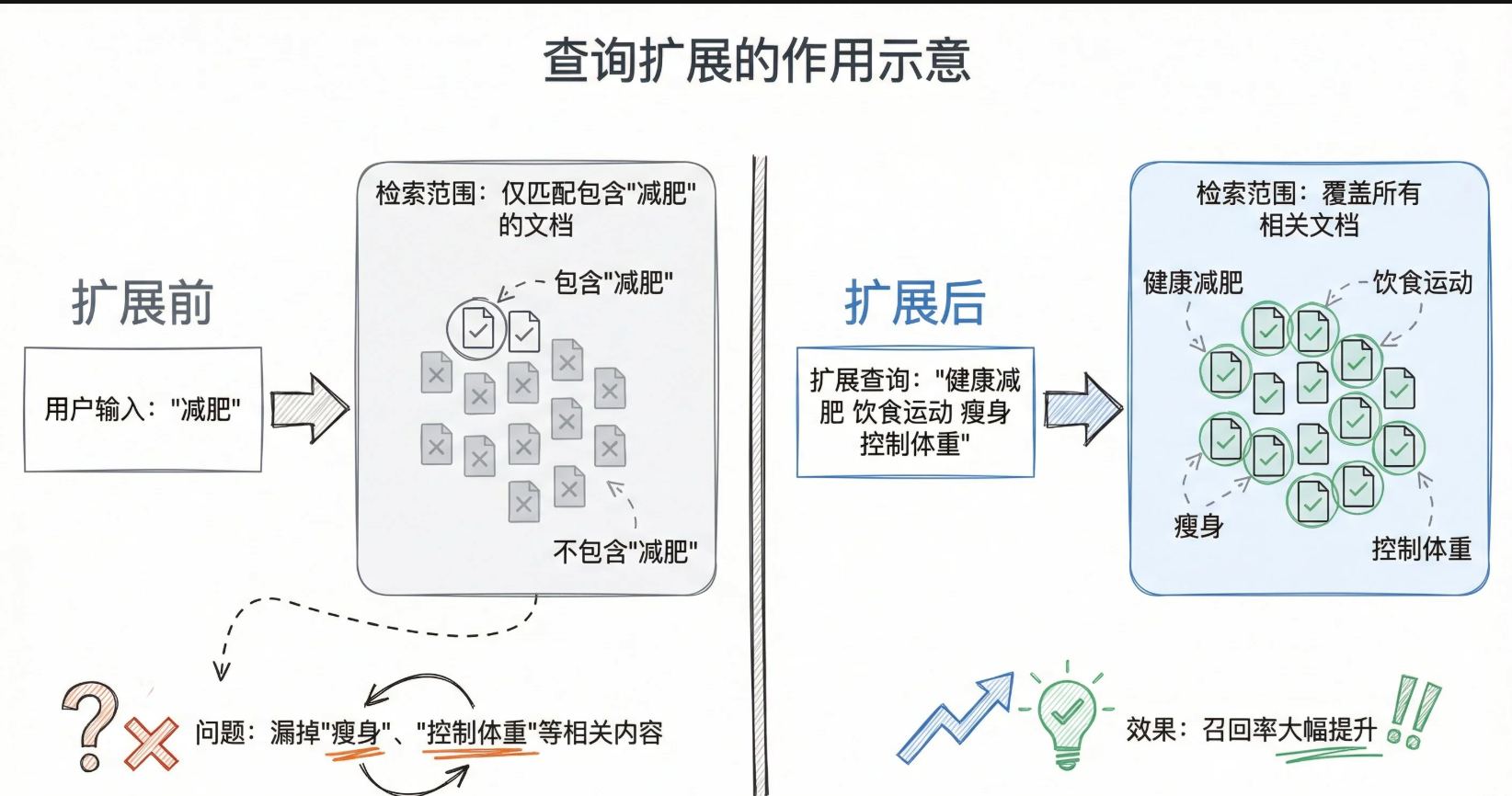
查询扩展就是把用户的原始问题补全,加上同义词、相关术语、隐含意图等这些信息,让检索能够覆盖更多相关文档,用户输入减肥,扩展后可能变成 健康减肥方法、饮食控制、运动减脂等
RAG的核心是 先检索后生成
检索如果没有查到高质量的东西,生成自然效果也不会好,查询扩展解决了两个痛点
- 词汇不匹配:用户说新冠,知识库里存的是COVID-19,如果不扩展就搜不到
- 查询太模糊:用户就输入怎么理财,扩展后就变成新手理财入门、低风险投资等,方向更明确

查询扩展发生在用户输入之后,检索之前,属于查询预处理阶段
常见的扩展方式有三种
- 基于规则的扩展
- 维护一份同义词词典,减肥对应瘦身、控制体重等,简单粗暴,适合垂直领域
- 基于LLM的扩展
- 让大模型直接改写查询,效果最好但是有延迟和成本
- 基于检索反馈的扩展
- 先用原始查询检索一轮,从top结果里提取高频词作为扩展词,即PRF,不依赖外部模型
扩展的度要把握好,扩展太少没效果,扩展太多引入噪音,生产环境一般控制在3-5个扩展词
用大模型做查询扩展会增加延迟,有没有办法优化
几个常用的优化手段
- 用小模型做扩展
- 扩展结果做缓存,同样的查询不重复调模型
- 异步扩展,原始查询先跑一路检索,扩展查询同时在跑,两路结果合并
- 热门查询预扩展,把高频的扩展结果提前存起来
查询扩展和混合检索的关系
二者可以配合使用
- 查询扩展解决的是查询词不准的问题
- 混合检索解决的是检索方式单一的问题
扩展后的查询即可以跑向量检索抓语义相关的,也可以走关键词检索,用BM25,然后两个结果在用加权求和或者RRF合并
如果扩展出来的词引入了噪声,怎么处理
- 事前在扩展的时候就控制质量,prompt明确要求只输出高度相关词汇
- 事后靠重排序兜底,rerank会把不相关的文档排到后面去
自查询
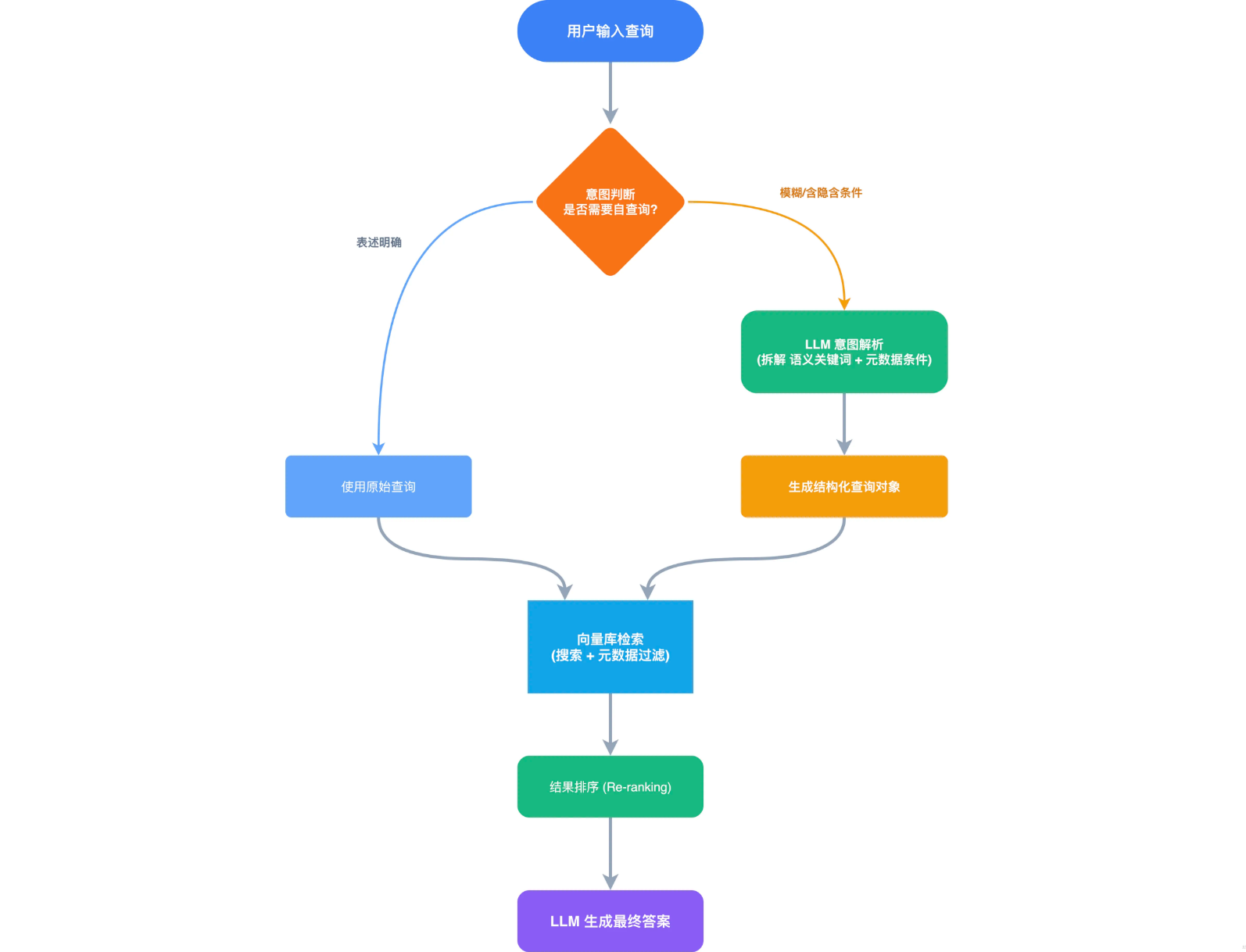
自查询(Self-Query)是RAG系统自动解析用户查询中的隐含条件的机制,把模糊的自然语言转成结构化查询语句
比如用户说“26年帆哥的用户报告”,自查询会拆成两部分
- 语义匹配:用户报告
- 元数据过滤:作者=帆哥,时间=2026
为什么需要自查询
用户提问往往带着隐含条件,传统向量检索只管语义相似度,压根不看元数据,结果就是检索出一堆语义相关但时间、作者、标签都不对的文档,自查询通过“解析+过滤”,让检索同时满足语义相关性和元数据条件,直接解决检索不准的痛点
自查询的工作流程
自查询发生在用户输入 到检索文档之间的意图解析阶段
python
{
"vector_search": {
"query_text": "风险控制策略 监管趋势",
"embedding_model": "text-embedding-3-large"
},
"metadata_filter": {
"must": [
{"field": "author", "operator": "=", "value": "李四"},
{"field": "date", "operator": ">=", "value": "2025-01-01"}
],
"should": [
{"field": "tags", "operator": "in", "value": ["金融", "风控"]}
]
},
"options": {
"limit": 10,
"score_threshold": 0.75
}
}自查询与查询扩展的对比
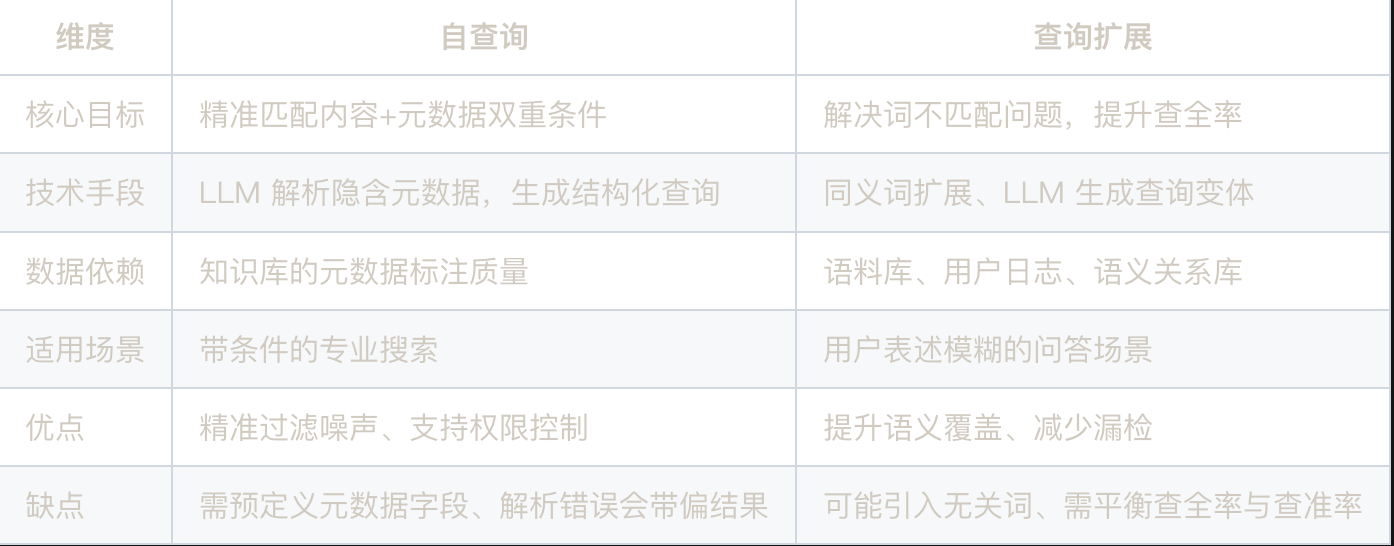
实际项目里可以两者配合用,比如先自查询过滤出“2026的用户报告”,再通过查询扩展补充其他关键词
如果知识库没有做元数据标注,自查询还能用吗
用不了,自查询的前提是文档入库的时候就打好了元数据标签,没有元数据,llm解析出来的过滤条件也没地方用,这种情况只能退回到纯语义检索,或者先补一轮元数据抽取,用NER模型或者LLM从文档内容里自动提取时间、作者、主题等字段
提示压缩
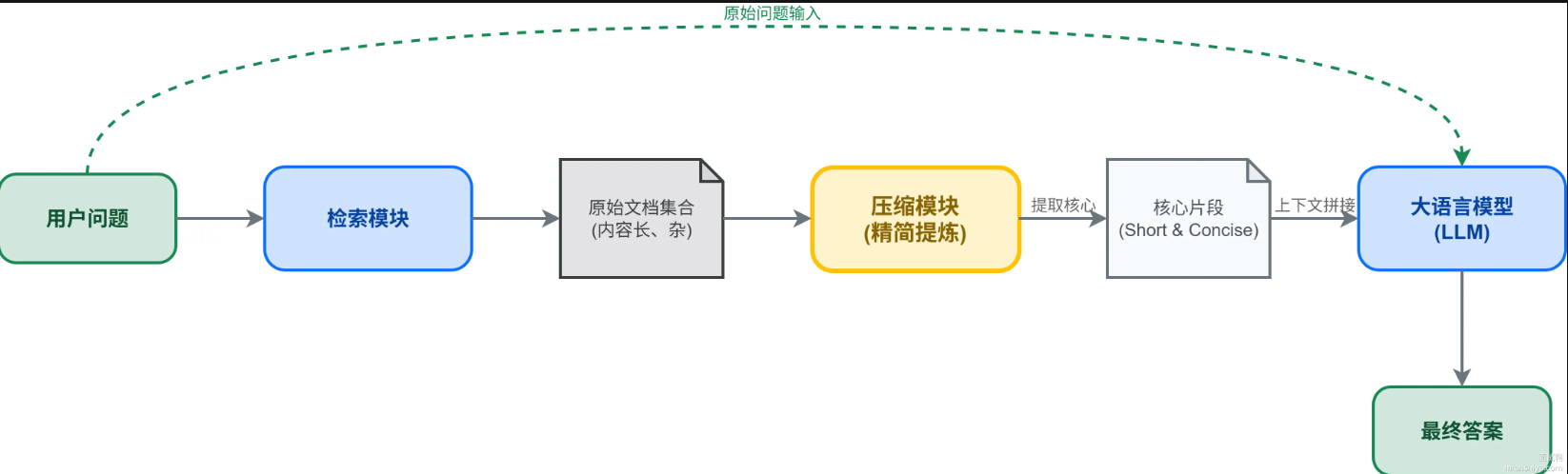
提示压缩是对检索出来的文档内容做精简处理,提取核心信息、过滤无关文本,让最终给大模型的内容保持关键信息,又能节省上下文空间
比如检索到一篇10页的技术白皮书,压缩后只保留跟用户问题相关的2个核心章节和关键数据,无关段落直接砍掉
为什么需要提示压缩
RAG的生成效果全靠喂给模型的文档质量,检索出来的文档通常有三个问题
- 上下文窗口有限,比如gpt-4 turbo是128k tokens, claude是200k tokens,听着很大,但是实际业务里面检索10篇文档很容易就超了,因此压缩能把关键信息浓缩进有限的token里
- 无关内容稀释重点,用户如果问”如何优化代码“,文档里80%是算法原理,只有20%是优化技巧,不压缩的话模型容易被原理部分带跑偏
- 省钱省时间,可以减少无关token
压缩方案落地
一般用小模型或者规则算法来做压缩
LLMLingua是微软开源的方案,基于信息熵评估每个token的重要性,把冗余内容直接砍掉,可以快速用LlamaIndex集成
python
from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="根据上下文回答问题"
)
contexts = retriever.retrieve(question)
compressed_contexts = node_postprocessor.process(contexts)
# instruction_str是压缩的指导方向,比如如下
# 强调保留关键实体
instruction_str = "保留文档中的人名、日期和数字"
# 任务导向压缩
instruction_str = "根据问题提取相关事实"
# 图文场景
instruction_str = "压缩文本时保留与图片中logo相关的描述"压缩会不会把关键信息压没了,如何保证压缩质量
核心是让压缩模块知道什么是关键
- 把用户问题作为压缩的锚点,跟问题相关性高的内容优先保留
- 设置压缩率上限,保留30%-50%是比较安全的区间
- 用NER提取关键实体,比如人名、日期、数字等硬性信息
- 上线前最好多测测,对比压缩前后的回答质量
长上下文模型出来了,还需要压缩吗
- 成本问题,窗口大了不代表免费
- 上下文越长,模型越容易走神,压缩掉无意义的文本意义还是很大的