Appearance
Embedding就是把文本、图像、音频这些人能理解的信息,转换成一串数字向量,让计算机能够理解和计算
有了向量表示,就可以通过数学计算判断两段话是否相关,最常用的就是余弦相似度,计算两个向量夹角的余弦值,值越接近1说明越相似
在RAG流程中,分块后的文本块先生成Embedding,存入向量数据库,用户提问时,系统把问题也转成EMbedding,然后在向量数据库中寻找相似度最高的几个文本块、
python
from sentence_transformers import SentenceTransformer
# 加载 embedding 模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 文本转向量
texts = ["如何煮奶茶", "奶茶制作步骤", "Python 入门教程"]
embeddings = model.encode(texts)
# 计算相似度
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity([embeddings[0]], [embeddings[1]])
# 输出约 0.85,说明"如何煮奶茶"和"奶茶制作步骤"语义相近为什么需要Embedding
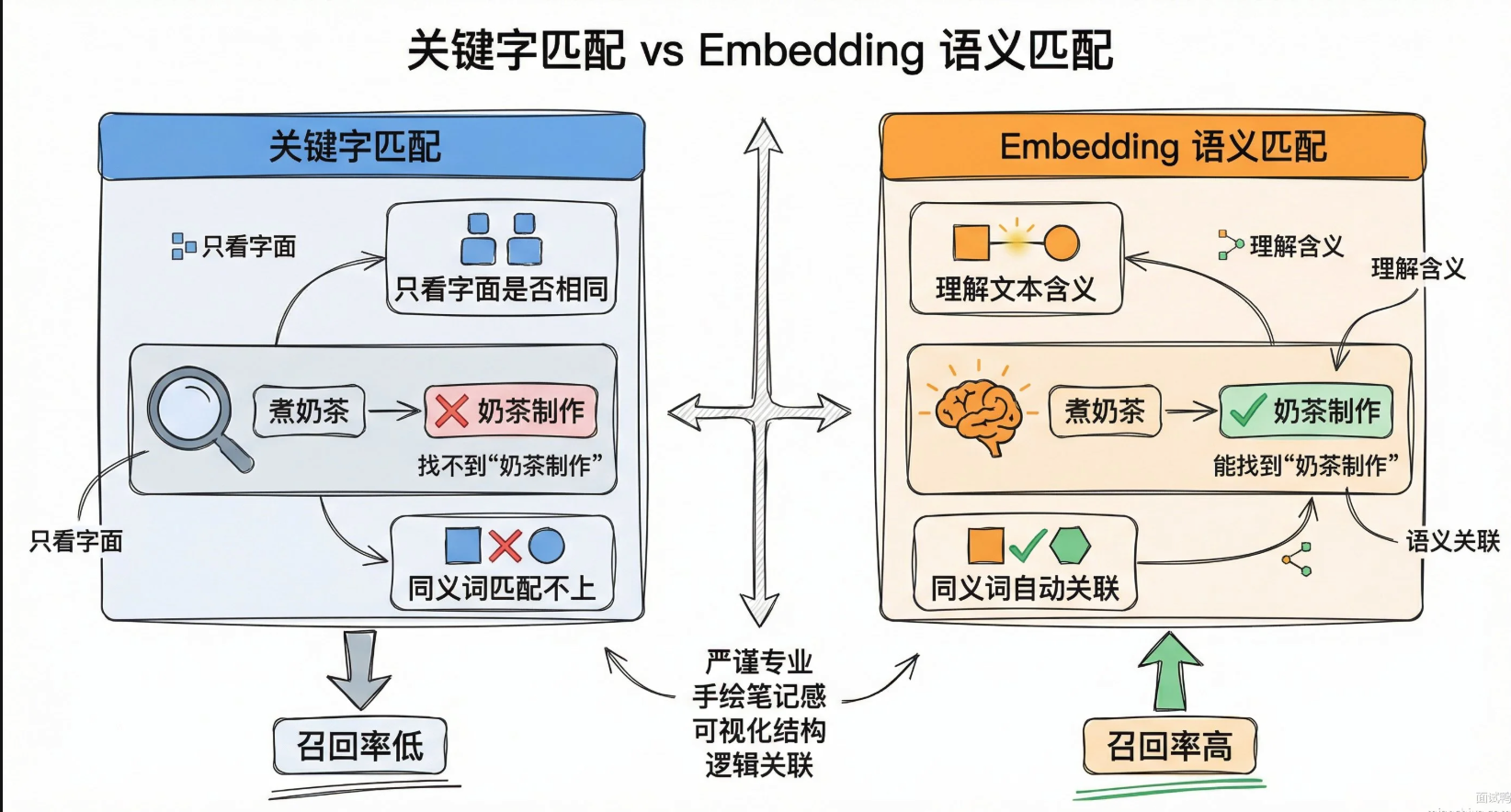
Embedding模型本质是个神经网络,输入一段文本,输出一个固定维度向量,比如openAI的text-embedding-3-small输出1536维,all-MiniLM-L6-v2输出384维
模型在训练的时候学会了把语义相近的文本映射到向量空间中的相近位置,训练数据是大量的文本对,标注了哪些是相关、哪些是不相关的
维度越高,能表的语义细节越丰富,但计算和存储成本越高
常用向量数据库
- Milvus:分布式向量数据库,支持水平扩展,适合需要高可用和弹性伸缩的生产环境
- Pinecone:全托管云服务,api简单,适合快速上线,不想折腾基础设施的团队
- Chroma:轻量级,纯python实现,嵌入式部署,适合本地开发和小规模应用
- Weaviate:支持混合搜索,向量检索和关键字检索可以结合用,适合需要融合多种检索方式的场景
Embedding模型

实际选型的话,中文场景选BGE或者M3E,英文场景选OpenAI或Cohere
轻量部署选Sentence-BERT

如何选择模型
综合考虑多方面因素
- 语义准确性
- 模型能不能准确捕捉文本语义,长句理解、上下文关联、同义词区分这些能力直接影响向量相似度计算的可靠性
- 模型效率
- 推理速度能不能满足业务实时性要求,qps高的不能用太大的模型
- 领域适配
- 是不是针对垂直领域做过预训练或微调
- 多语言支持
- 是否支持业务所需语言,跨语言对齐能力如何
- 数据规模匹配
- 模型参数量和训练数据规模要匹配预料复杂度,小数据用大模型容易出现过拟合,大数据用小模型会出现语义坍塌
- 开放性与生态
- 是否开源、社区是否活跃、能不能定制微调、api调用是否灵活
- 成本
- 计算成本、使用成本