Appearance
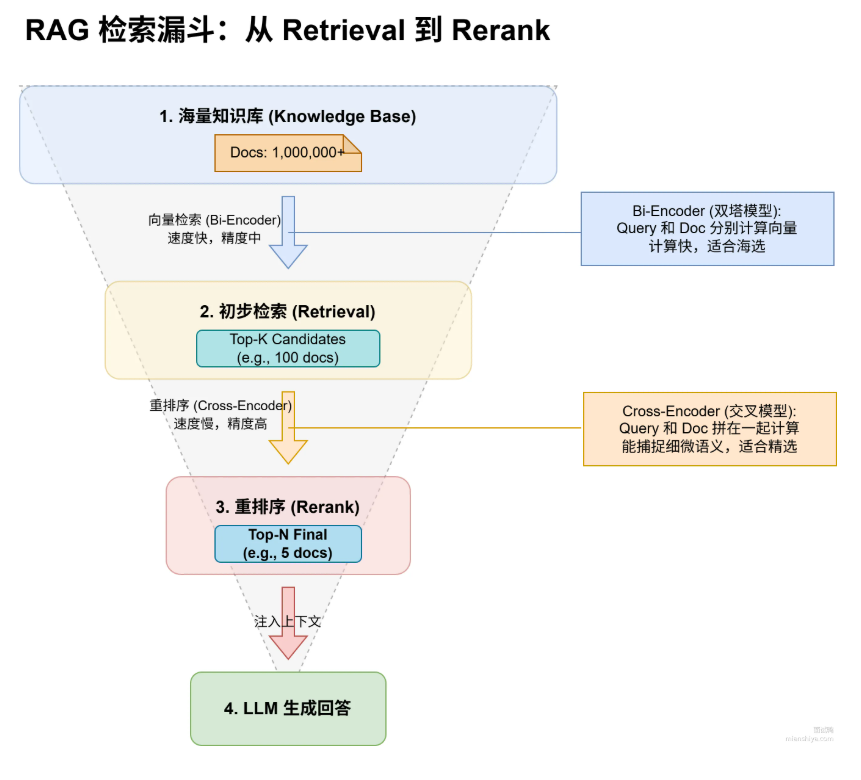
Rerank是一个对初步检索返回的候选文档列表在进行排序的过程
可以把RAG检索过程想象成公司招聘
- 1、初步检索(Retrieval)
这就像HR筛选简历,海选,对应我们常用的向量检索(Bi-Encoder),它算的快,但是对语义理解没有那么深,只能选出来Top100个看起来还行的候选人
- 2、重排序(Rerank)
这就像业务主管面试,精选,通常是(Cross-Encoder),它能精准判断这个文档是不是真的能回答用户的问题,即从100个人中挑出Top-5个最匹配的,然后再喂给大模型生成答案
Rerank的核心价值就是在速度和精度中做一个平衡,先用向量检索保速度,再用Rerank保精度
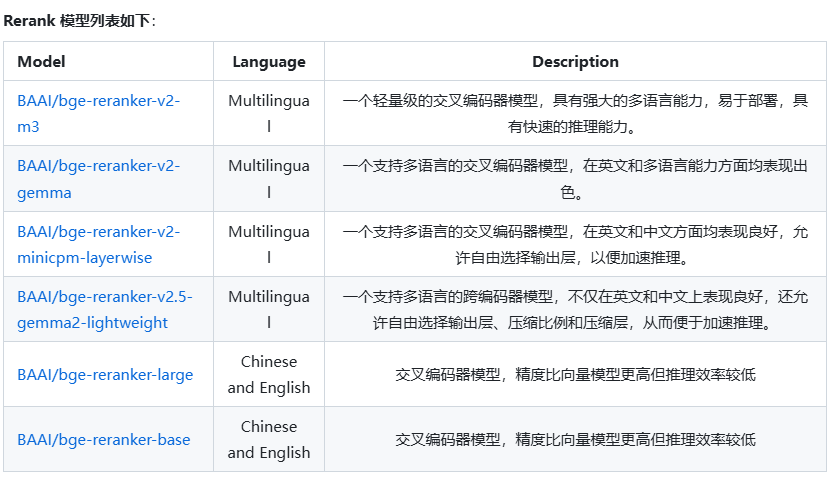
常见的Rerank模型
其他参考文档:https://techdiylife.github.io/blog/blog.html?category1=c02&blogid=0049
Rerank的延迟一般有多少,对整体RAG系统性能影响大吗
- Cross-Encoder的Rerank延迟通常在50-200ms左右,具体取决于模型大小和候选文档数量,如果召回100个文档,每个文档平均500tokens,用bge-reranker-base再gpu上跑大概100ms左右,对整体rag来说,向量检索通常只要10-50ms,rerank这一步反而成了瓶颈,因此要控制召回数量,一般50-100个就够了
除了Cross-Encoder,还有什么别的Rerank方案
- ColBERT 延迟交互模型,把Document的token级向量提前算好,Query来了只需要做token级别的相似度匹配,比Cross-Encoder快并且精度相近
- 用LLM直接做Rerank,把候选文档和Query喂进去让他打分,效果好但是成本高
- 基于规则的Rerank,比如优先最近更新的文档,优先特定来源的文档,简单场景够用
如果Rerank模型和Embedding模型对同一个文档的打分差异很大,应该信谁
- 信Rerank, Embedding模型用的是Bi-Encoder架构,Query和Document没有直接交互,只是各自编码后算相似度,语义理解比较浅
- Rerank的Cross-Encoder是把Query和Document拼一起过Transformer,有充分的注意力交互,对语义匹配的判断更准,Embedding负责快速召回,Rerank负责精准排序