Appearance
HNSW
分层可导航小世界图,把所有向量组织成多层图结构,查询时从上层稀疏图贪心跳转,逐层下探到底层密集图,快速定位近似最邻近点,Milvus,Qdrant默认用这个
核心思想来自”小世界网络“理论,任意两点之间只需要6步就能到达
构建过程:每插入一个新向量,随机决定它能到达的最高层,层级越高概率越小,大概呈指数分布,然后从最高层开始,贪心找当前层最近的邻居,连边,再下探到下一层重复这个过程
查询过程:从顶层的入口点开始,贪心跳到当前层最近的邻居,直到没有更近的为止,然后下探到下一层,到了底层就在局部区域内做精细搜索,返回top-k
关键参数
- M:每个节点的邻居数,越大图越稠密,召回率越高但是内存也越大,一般设置16-64
- efConstruction:构建时的搜索宽度,越大索引质量越好,但是构建越慢,一般设置100-200
- efSearch:查询的时候的搜算宽度,越大召回率越高但是查询越慢,可以动态调整
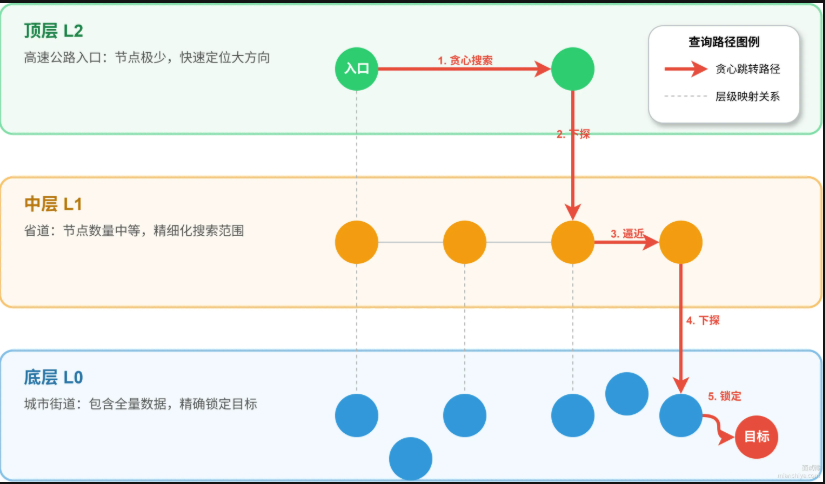
HNSW分层结构示意
- 顶层L2:只有2-3个节点,像高速公路入口
- 中层L1:节点数量中等,像省道
- 底层L0:包含所有节点,像城市街道
- 查询路径:从L2入口开始,贪心跳转寻找最近邻居,逐层下探到L0
LSH原理详解
LSH的关键是设计乙租哈希函数,让相似向量有高概率哈希到同一个桶,不相似向量有高概率哈希到不同桶
常见的LSH家族
- 随机投影LSH:用随机超平面切分空间,向量落在超平面哪一侧就编码为0或者1,多个超平面组合成哈希码,适合余弦相似度
- MinHash:用于集合相似度,把集合元素哈希后取最小值做签名,适合Jaccard相似度,常用于文档去重
- SimHash:把高维向量降维成二进制指纹,距离近的向量原始相似度也高,google用它做网页去重
LSH的优势是查询复杂度接近O1,不管数据量多大,只要桶分的好,查询时间几乎不变,但是召回率不大稳定,可能会漏掉一些相似向量
实际使用中常见的作法是多表LSH,建多张哈希表,每张表用不同的哈希函数族,查询时取所有表命中的候选集的并集,再做精排,表越多召回率越高,但是存储和查询的开销就越大
PQ
PQ的核心思想是分治,把一个高维向量拆成M个低维子向量,每个子空间独立做聚类量化
具体步骤
- 训练步骤,把所有向量按维度切成M段,独立跑K-Means聚类,得到M组码本,每组有K个聚类中心
- 编码阶段,对于每个向量,找到每段子向量最近的聚类中心,用中心的编号代替原始值,M段就用M个编号表示整个向量
- 查询阶段,先计算查询向量每段到所有聚类中心的距离,存成查找表,然后对库里每个编码向量,查表求和就能得到近似距离,不用算原始向量
HNSW的M参数设大或者设小了会怎么样
- M是每个节点的最大邻居数,设大了,图就变得稠密,搜索时能搜索更多路径,召回率会上去,但是内存占用也线性增长
- 设小了图变稀疏,可能出现孤岛导致某些区域搜索不到,召回率会下降
- 一般M=16是个平衡点,追求高召回可以调到32-48
LSH召回率为什么不稳定,怎么改进
- LSH依赖哈希函数把相似向量分到同一个桶,但这是概率性的,两个相似度高的向量可能因为落在哈希边界上被分到不同桶,直接漏掉
- 改进方案
- 多表LSH,建10-20张不同哈希函数的表,查询时取并集
- 扩大搜索范围,不只看目标桶,临近的桶也都扫一遍
- 把LSH当粗筛,后面接精排环节
PQ压缩后精度损失多大
- 取决于子空间划分和聚类数量
