Appearance
LLM原生的上下文窗口只有几千到十几万的tokens,聊的多了前面的内容就被挤出去了,所以要给Agent加长期记忆,就得借助外部机制
主流方案有两种
- 向量数据库+RAG
- 把历史对话和知识转为向量embeddings,存进Pinecone、ChromaDB、Milvus等向量库,新会话来了,先根据用户输入检索相关的历史内容,把检索结果塞进去prompt,LLM就可以“回忆”起来之前聊过什么,这是目前最成熟、落地最多的方案
- 分层记忆体系
- 把记忆分成短期和长期两层,短期记忆就是当前会话的上下文,长期记忆是压缩后的关键信息摘要或者embeddings, Memgpt就是这个思路,它借鉴操作系统的虚拟内存机制,把记忆分为main context和archival storage,按需换入换出
MemGPT的分层记忆架构
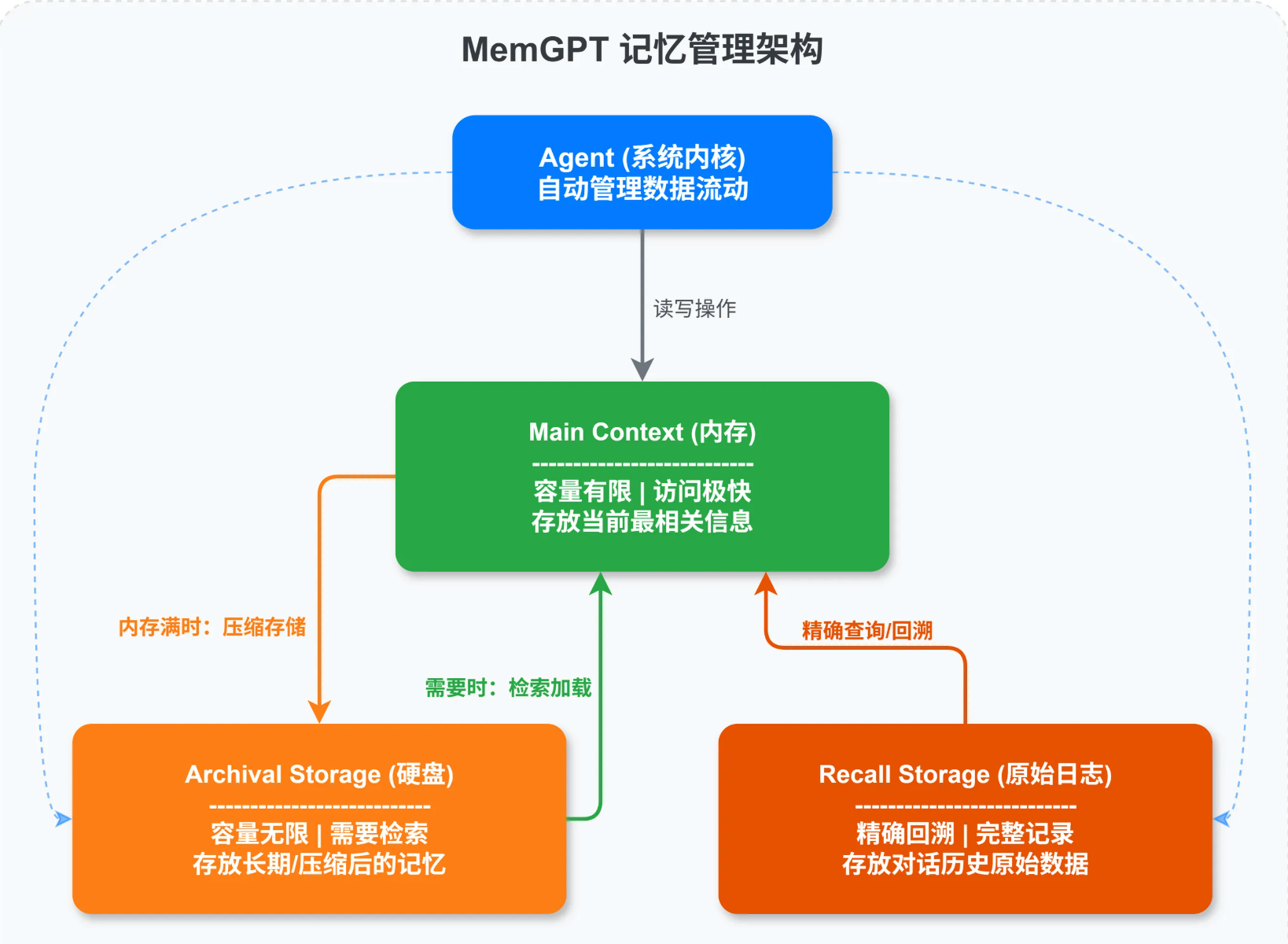
它借鉴了操作系统的虚拟内存概念
Main Context
- 相当于内存,容量有限但是访问快,存放当前对话最相关的信息
ASrchival Storage
- 相当于硬盘,容量几乎无限但是访问需要检索,存放所有历史记录
Recall Storage
- 专门存放对话历史的原始记录,需要时可以精确回溯到某一轮对话
长上下文技术的新发展

落地时的工程考量
- 存储成本
- 向量库存几百万条记录问题不大,但是如果到了千万、亿级别,存储和索引成本会急剧上升,可以考虑分层存储,热数据用内存数据库,冷数据用磁盘
- 检索延迟
- 向量检索本身很快,通常几十毫秒,如果数据量大,检索top-k设的高,延迟就会上去,可以用ann算法做近似检索,牺牲一点精度还速度
- 数据隐私
- 用户的历史对话属于敏感数据,存储和检索都要做权限隔离,每个用户的记忆只能自己访问不能串到别人那
- 记忆更新
- Agent的记忆应该支持更新和删除,比如用户说忘掉我之前说的,要真的能删掉对应的记忆条目
