Appearance
在深入Transformer的技术细节之前,有必要先理解它试图解决的根本问题:
- 如何对序列数据进行有效建模
一、什么是序列建模
序列建模是指让计算机理解和处理有序数据的任务,自然语言是最典型的序列数据,一句话中的词语的排列顺序直接决定了语义
序列建模覆盖了NLP中的绝大多数核心任务
- 语义建模:给定前文,预测下一个词,比如输入法联想
- 机器翻译:将一种语言的句子转化为另一种语言
- 文本分类:判断一段文字的情感、主题、意图
- 序列标注:为每个词标注词性、实体类型等标签
- 文本生成:根据提示生成连贯的段落或文章
所有这些任务的共同核心是:模型必须理解元素之间的顺序关系和依赖关系
二、序列建模的三大核心难度
任何序列模型都必须同时解决三个相互关联的挑战,这也是Transformer能诞生的根本原因
- 变长输入问题,与图像不同,句子的长度可以从一个词到数千个词不等,模型必须能够处理任意长度的输入,而不是假设固定大小的数据,传统的全连接网络要求输入维度固定,这使得它无法直接处理变长序列
- 长距离依赖问题,语言中的依赖关系可能跨越很多的距离,但模型必须正确地将他们关联起来,这种长距离依赖的捕捉能力,直接决定了模型理解复杂语义的能力
- 计算效率问题,处理序列的速度至关重要,如果一个模型必须严格按顺序逐个处理每个元素,那么对于长序列,计算时间将线性增长,且无法利用现代硬件(如 GPU)的并行计算能力。训练速度的瓶颈直接限制了模型的规模和数据的吞吐量。
围绕这三大根本难题,序列建模领域展开了长达几十年的探索与发展。在这段漫长的技术演进中,循环神经网络(RNN)较好地解决了变长输入问题,随后的长短期记忆网络(LSTM)在长距离依赖问题上取得了显著改善。然而,直到 Transformer 横空出世,计算效率问题才真正迎来了突破——不仅如此,它在前两个问题上也给出了更为优雅的答案。
三、从统计方法到神经网络
在深度学习之前,序列建模主要依赖统计方法
N-gram语言模型是早期最成功的方案之一,它的思路很直接,用前n-1个词来预测第n个词,概率通过语料库中的统计频率来估算。
例如,一个 3-gram(三元组)模型会根据“我 喜欢”来预测下一个词可能是“你”或“吃”等。

隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)等概率图模型提供了更强的建模能力,但它们同样受限于马尔可夫假设——当前状态只依赖于有限的前序状态。
神经网络的引入改变了游戏规则。从 2003 年 Bengio 等人的前馈神经网络语言模型开始,研究者发现可以将词表示为连续向量(词嵌入),让模型在一个连续的语义空间中处理语言
四、从文字到向量:模型看到的是什么
上文提到了词嵌入把词表示为连续向量。但“文本是怎样变成向量的”这个问题值得在此做一个直觉性的梳理——理解这条管线,是理解后续所有序列模型(从 RNN 到 Transformer)的前提。
神经网络只能处理数值,不能直接“阅读”文字。因此,模型在接收到一段文本后,必须经过以下三个阶段才能开始计算:
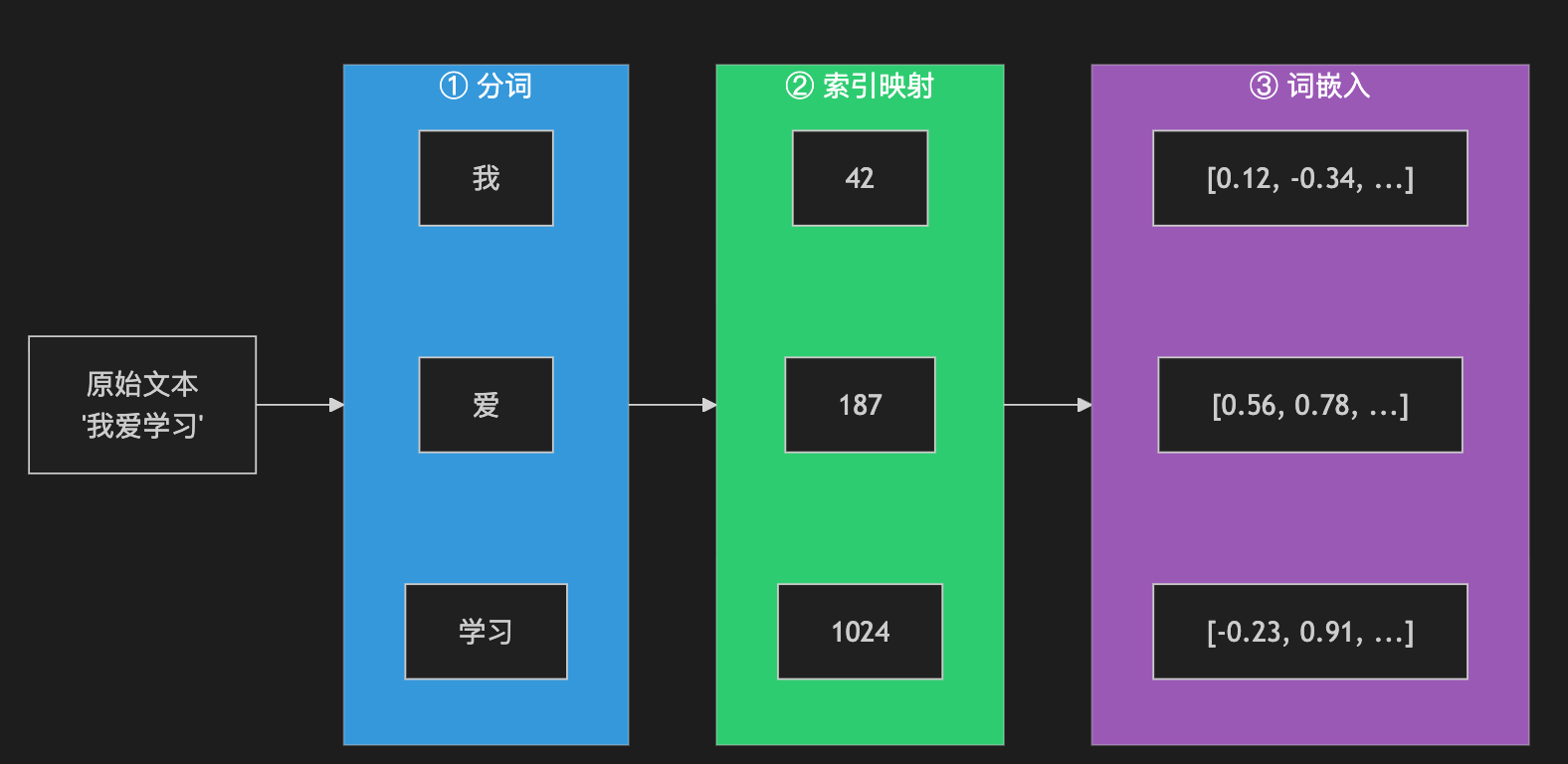
第一步,分词(Tokenization)。 将原始文本切分为一系列基本单元,称为词元(Token)。词元既可以是一个完整的词,也可以是一个子词片段甚至一个字符。例如,“我爱学习”可能被切分为“我”、“爱”、“学习”三个词元;而英文单词“tokenization“可能被切分为”token“和”ization“两个子词。这种子词分词策略是现代大语言模型的标准做法,它在词汇覆盖率和序列长度之间取得了良好的平衡。
第二步,索引映射。 每个词元在预先构建的词汇表(Vocabulary)中有一个唯一的整数索引。分词器将词元序列转换为整数索引序列。例如,”我”→ 42,“爱”→ 187,“学习”→ 1024。
第三步,词嵌入(Embedding)。 模型内部维护一个嵌入矩阵,每一行对应词汇表中一个词元的向量表示。通过查找索引对应的行,每个词元被映射为一个固定维度的稠密向量。这些向量就是神经网络真正“看到”和处理的输入。